# HashMap 结构
HashMap 采用数组 + 链表 + 红黑树的存储结构。当一个键值对要存储到 HashMap 中时,HashMap 会根据它的键值的哈希值映射到数组的某个位置。如果发生了哈希碰撞,就以链表的形式接在碰撞元素的后边。当链表过长时,就会转变为红黑树。
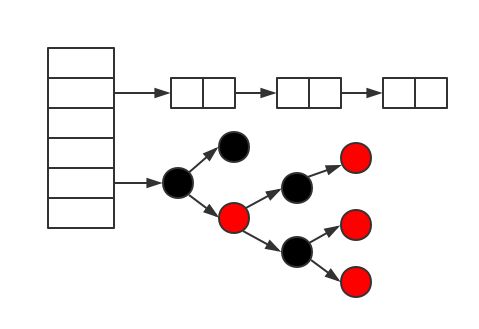
下边我们就先来看下链表和红黑树的数据结构。
# 链表
内部类 Node 定义了链表的每个结点的结构,它记录结点的 hash、key、value 和下一个结点 next。
final int hash; | |
final K key; | |
V value; | |
Node<K,V> next; |
# 红黑树
内部类 TreeNode 定义了红黑树每个结点的结构,每个结点都保存了父结点、左结点、右结点、颜色以及一个在删除时需要解除连接的(其实这个我也不知道是干啥的)。
TreeNode<K,V> parent; // 父结点 | |
TreeNode<K,V> left; // 左结点 | |
TreeNode<K,V> right; // 右结点 | |
TreeNode<K,V> prev; // 前一个结点 | |
boolean red; // 是否是红色 |
# 结构实现细节
首先来看下 HashMap 中的变量。
transient Node<K,V>[] table; //table 存储 HashMap 中数组的元素 | |
transient Set<Map.Entry<K,V>> entrySet; // 遍历的入口,可以获取到 key 和 value | |
transient int size; // HashMap 的已存储元素的个数 | |
transient int modCount; // 被修改的次数 | |
int threshold; // 扩容的阈值 | |
final float loadFactor; // 装载因子 |
size 是 HashMap 中已经存储的元素的个数,它并不等于 table 的长度,也不等于 table 中已存储的元素的个数。如下图的 HashMap,它的 size 大小是 14。

HashMap 的扩容机制并不像 ArrayList 等,在容量不够用时才会扩容。HashMap 在容量达到某个百分比时就会开始扩容,这个百分比就是 loadFactor,threshold 就是对应这个百分比的容量,即 capacity * loadFactor。HashMap 中将 loadFactor 的默认值设为 0.75f。
static final float DEFAULT_LOAD_FACTOR = 0.75f; |
我们大概了解到,链表达到某个长度会转变为红黑树。HashMap 中定义了这个长度的阈值为 8。
static final int TREEIFY_THRESHOLD = 8; |
当红黑树的结点数小于某个值时,又会变为链表,HashMap 将其设定为 6。
static final int UNTREEIFY_THRESHOLD = 6; |
如果数组的长度太小,会造成哈希碰撞频繁,链表结构臃肿,所以 HashMap 定义了阈值,当 HashMap 的容量小于这个值时,优先去扩容减小哈希碰撞,而不是去优化链表的结构。
static final int MIN_TREEIFY_CAPACITY = 64; |
# 构造方法
HashMap 的初始容量和装载因子可以由开发者设定,也可以使用 HashMap 提供的默认值。对应的构造方法有三种。还可以根据一个 Map 来构造一个 HashMap。
指定容量和装载因子。
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 不能超过最大容量if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}首先指定的容量不能超过最大容量,HashMap 对最大容量的设定为 2^30。
static final int MAXIMUM_CAPACITY = 1 << 30;
当指定容量不超过最大容量时,也需要对指定容量进行处理,使之成为 2 的倍数,我们首先来看一下如何取得一个数的 2 的倍数,并且这个 2 的倍数大于这个数,也最贴近这个数。
下面是取得 2 的倍数的方法,一堆的位移操作想必一定把很多人搞晕了,我们来仔细分析一下。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}n = 100 0000 0000 0000 0000 0000 0000 0000。
第一步: n |= n >>> 1
![]()
第二步:n |= n >>> 2
![]()
第三步:n |= n >>> 4
![]()
第四步:n |= n >>> 8
![]()
第五步:n >>> 16
![]()
可以看出,这个方法的操作相当于,从最高位 1 开始,低位都填充 1。
弄清楚了这几个位移的操作就不难理解这个方法了,首先将参数减 1,最后再加 1。有效位都是 1 的数加 1 就是 2 的倍数。如果指定容量已经是 2 的倍数,先减 1 再位移可避免再扩大 2 倍。
指定容量
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}指定容量时使用默认装载因子。
不指定容量和装载因子
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}无参构造时,使用默认装载因子,不设定容量大小。
根据 Map 构造
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}根据 Map 构造 HashMap 时,使用默认装载因子。然后将 map 中的值放入。





# 常用方法
- 增
public V put(K key, V value) { | |
return putVal(hash(key), key, value, false, true); | |
} | |
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { | |
Node<K,V>[] tab; Node<K,V> p; int n, i; | |
// 数组为空或者长度为 0 先扩容 | |
if ((tab = table) == null || (n = tab.length) == 0) | |
n = (tab = resize()).length; | |
// (n - 1)&hash 计算出应放置在数组中的位置 | |
// 如果数组的对应位置上没有元素,就直接放在数组中 | |
if ((p = tab[i = (n - 1) & hash]) == null) | |
tab[i] = newNode(hash, key, value, null); | |
// 发生哈希碰撞 | |
else { | |
Node<K,V> e; K k; | |
// 先判断一下 hash 是否相等,再判断 key 是否相等,相等就替换 | |
if (p.hash == hash && | |
((k = p.key) == key || (key != null && key.equals(k)))) | |
e = p; | |
// 是红黑树的结点就放在红黑树中 | |
else if (p instanceof TreeNode) | |
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); | |
else { | |
// 是链表的结点放在链表中,但是要判断一下链表是否需要转化为红黑树 | |
for (int binCount = 0; ; ++binCount) { | |
if ((e = p.next) == null) { | |
p.next = newNode(hash, key, value, null); | |
if (binCount >= TREEIFY_THRESHOLD - 1) | |
treeifyBin(tab, hash); | |
break; | |
} | |
// 有相同的 key 就替换旧值 | |
if (e.hash == hash && | |
((k = e.key) == key || (key != null && key.equals(k)))) | |
break; | |
p = e; | |
} | |
} | |
// 赋新值并返回旧值 | |
if (e != null) { | |
V oldValue = e.value; | |
if (!onlyIfAbsent || oldValue == null) | |
e.value = value; | |
afterNodeAccess(e); | |
return oldValue; | |
} | |
} | |
// 修改次数加 1 | |
++modCount; | |
// 达到容量阈值就扩容 | |
if (++size > threshold) | |
resize(); | |
afterNodeInsertion(evict); | |
return null; | |
} |
看到 (n - 1)&hash,我们一定会有疑问,为什么这个计算就可以获取到值应该放置的位置呢?
根据之前我们的分析,我们知道 n - 1 的每一个有效位都为 1,那么与操作就可以拿到 hash 的二进制中 n - 1 的有效位的值,即 hash % (n - 1) 的值。这就是二进制 0 和 1 的魅力呀。比如 n = 32,hash = 1010011001:

查
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 数组中对应位置有值if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) {
// 数组中元素的 value 是我们要的if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 要的元素在链表或红黑树中if ((e = first.next) != null) {
// 在红黑树中if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
// 链表中找到了元素if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}}return null;
}删
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}final Node<K,V> removeNode(int hash, Object key, Object value, boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// 数组对应位置有元素if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 要移除的元素在数组中if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
// 要移除的元素在红黑树中if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
// 要移除的元素在链表中if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}p = e;
} while ((e = e.next) != null);
}}// 到此为止如果要删除的元素存在,就已经拿到了结点// 要删除的结点不为空并且判断需不需要判断传入 value 和要删除的结点 value 的相等if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// 是红黑树的结点调用红黑树的删除结点方法if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
// 是数组中的元素else if (node == p)
tab[index] = node.next;
// 是链表中的结点elsep.next = node.next;
// 修改次数加 1++modCount;
// 大小减 1--size;
afterNodeRemoval(node);
return node;
}}return null;
}
# JDK 8 新增方法
getOrDefault(Object key, V defaultValue)
获取 key 的值,当 key 的值为 null 时返回指定的 defaultValue。
putIfAbsent(K key, V value)
当 key 的值为 null 或者不存在 key 时向 HashMap 中添加元素。
remove(Object key, Object value)
当指定的 key 和 value 都正确时才将其移除掉。
replace(K key, V oldValue, V newValue)
如果指定的 key 和 oldValue 正确就用 newValue 替换掉 oldValue。
replace(K key, V value)
key 存在的话直接将值替换为 value。
computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)
如果 key 的值为 null 或者不存在就使用指定函数执行 key,并将返回值设为对应的值。
public V computeIfPresent(K key, BiFunction<? super K, ? super V, ? extends V> remappingFunction)
如果存在就使用指定函数执行 key 和 oldValue,并将返回值设为新值。
merge(K key, V value, BiFunction<? super V, ? super V, ? extends V> remappingFunction)
如果 key 对应的值不为空,就使用指定函数执行 oldValue 和 value,并将返回值设为新值。
forEach(BiConsumer<? super K, ? super V> action)
对每一个元素都执行指定操作。
replaceAll(BiFunction<? super K, ? super V, ? extends V> function)
将每个元素都替换为执行函数之后的返回值。
# 扩容机制
resize 方法对 HashMap 进行扩容,我们来分析此方法就可以了解到 HashMap 的扩容机制。
final Node<K,V>[] resize() { | |
// 原来的数组 | |
Node<K,V>[] oldTab = table; | |
// 原来的容量 | |
int oldCap = (oldTab == null) ? 0 : oldTab.length; | |
// 原来的扩容阈值 | |
int oldThr = threshold; | |
// 新的容量和阈值 | |
int newCap, newThr = 0; | |
// 原来的容量大于 0 | |
if (oldCap > 0) { | |
// 如果原来的容量大于等于最大容量,就将扩容阈值设为 Integer 的最大值 | |
if (oldCap >= MAXIMUM_CAPACITY) { | |
threshold = Integer.MAX_VALUE; | |
return oldTab; | |
} | |
// 如果原来的容量的 2 倍不超过 HashMap 的最大容量,并且原来的容量大于 HashMap 的默认初始容量 | |
// 就将扩容阈值扩大两倍 | |
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && | |
oldCap >= DEFAULT_INITIAL_CAPACITY) | |
newThr = oldThr << 1; | |
} | |
// 原来的容量为 0,但是原来的扩容阈值大于 0 | |
else if (oldThr > 0) | |
// 将新的容量设为原来的扩容阈值 | |
newCap = oldThr; | |
// 原来的容量和扩容阈值都为 0 | |
else { | |
// 新的容量设为默认初始容量,新的扩容阈值设为默认装载因子 * 默认初始容量 | |
newCap = DEFAULT_INITIAL_CAPACITY; | |
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); | |
} | |
// 新的扩容阈值为 0 | |
if (newThr == 0) { | |
// 计算扩容阈值 | |
float ft = (float)newCap * loadFactor; | |
// 如果新的容量小于最大容量并且新容量对应的扩容阈值小于最大容量 | |
// 就将新的扩容设为 ft,否则就将新的扩容阈值设为 Integer 的最大值 | |
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); | |
} | |
// 设置扩容阈值 | |
threshold = newThr; | |
// 申请一个新的 table | |
@SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; | |
table = newTab; | |
// 如果原来的数组中有元素,就将原来的 HashMap 中的元素移到新的数组中 | |
if (oldTab != null) { | |
for (int j = 0; j < oldCap; ++j) { | |
Node<K,V> e; | |
// 数组对应位置有元素 | |
if ((e = oldTab[j]) != null) { | |
oldTab[j] = null; | |
// 没有链表或者红黑树 | |
if (e.next == null) | |
newTab[e.hash & (newCap - 1)] = e; | |
// 当前桶是红黑树 | |
else if (e instanceof TreeNode) | |
((TreeNode<K,V>)e).split(this, newTab, j, oldCap); | |
// 当前桶是链表 | |
else { | |
Node<K,V> loHead = null, loTail = null; | |
Node<K,V> hiHead = null, hiTail = null; | |
Node<K,V> next; | |
// 遍历链表,并分为两组 | |
do { | |
next = e.next; | |
if ((e.hash & oldCap) == 0) { | |
if (loTail == null) | |
loHead = e; | |
else | |
loTail.next = e; | |
loTail = e; | |
} | |
else { | |
if (hiTail == null) | |
hiHead = e; | |
else | |
hiTail.next = e; | |
hiTail = e; | |
} | |
} while ((e = next) != null); | |
// 将两组链表放到新的数组中 | |
if (loTail != null) { | |
loTail.next = null; | |
newTab[j] = loHead; | |
} | |
if (hiTail != null) { | |
hiTail.next = null; | |
newTab[j + oldCap] = hiHead; | |
} | |
} | |
} | |
} | |
} | |
return newTab; | |
} |
总的来说,有以下几种情况:
当目前容量大于等于最大容量时,扩容阈值设为整型最大值。
当当前容量不超过最大容量且扩大 2 倍之后也不超过最大容量时,扩容至 2 倍,新的扩容阈值扩大至 2 倍。
当当前容量不超过最大容量但是扩大 2 倍之后会超过最大容量时,扩容至 2 倍,就将扩容阈值设为整型最大值。
当当前容量为 0 且当前扩容阈值大于 0 时,扩容至原来阈值大小,阈值变为新容量乘以装载因子。
当当前容量和扩容阈值都等于 0 时,容量设为默认初始容量大小,阈值设为默认容量乘以默认装载因子,

# 总结
总的来说,HashMap 就是围绕数组 + 链表 + 红黑树的结构展开的。关于红黑树的具体细节,会在另一篇博客中展开分析。